
Charlotte Eisenberg ’19 is a college basketball fan. In addition to being a fixture at the Haverford teams’ home games, she also decided to start supporting nearby Villanova during her first year of college so as to have a Division 1 rooting interest. (It was a pretty good choice, given that Nova won the NCAA tournament that year, and Eisenberg was able to watch national title game surrounded by fans at Villanova.) But the math major’s interest goes beyond game attendance and cheering.
Inspired by meeting Davidson College Professor Tim Chartier during the spring 2016 Bi-Co Math Colloquium, Eisenberg, who is also concentrating in in mathematical economics, began work on independent projects related to sports analytics. A player on the Haverford Field Hockey Team, she began that research with her team’s stats. Then, after earning funding through the KINSC-administered Velay Fellowship, she headed to Davidson’s North Carolina campus last summer to conduct research with Chartier. That research, which included studying the NBA’s “hot hand” phenomenon and helping to design a kid-friendly math game for an event at New York’s Museum of Math, also involved a research project of her own. Eisenberg developed an algorithm to predict outcomes in the NCAA Division I March Madness Men’s Basketball Tournament.
“I finished my project in August and was able to backtest five years and demonstrate that my algorithm would have outperformed other methods, including fivethirtyeight, Power Rank, and numberFire,” said Eisenberg, whose favorite book is The Signal and The Noise by fivethirtyeight founder Nate Silver. “But I knew the first real test would come now, in March, as my algorithm first tackles a tournament field in real time.”
Looking for help with your bracket? Below, Eisenberg—who is currently studying abroad in Budapest but still plans to watch this year’s tournament’s games, even though they can start at 2 a.m. or later in her local time—talks you through her algorithmically generated table of this year’s teams and what her predictions could mean for your office pool.
What am I looking at?
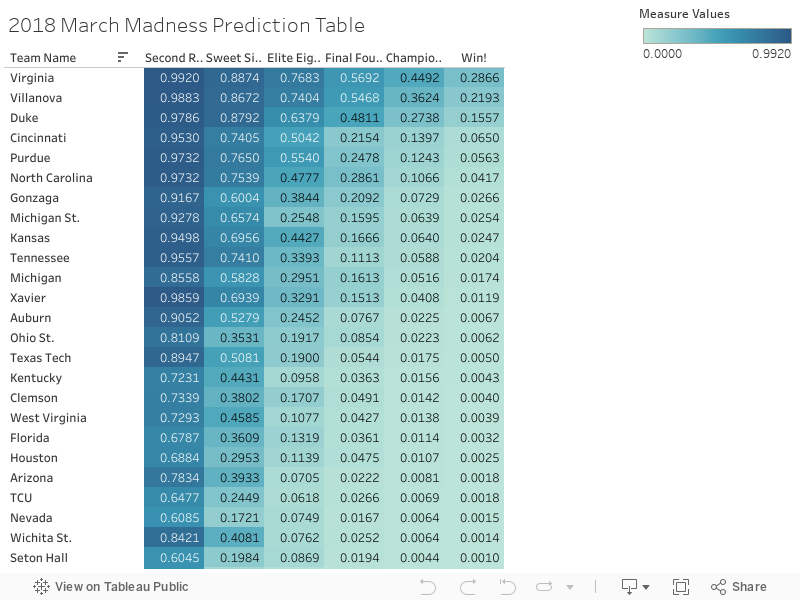
Each row of this table represents one of 64 teams in the 2018 March Madness Tournament. Choose a team in the first column and move to the second column to see the probability that that team will appear in the second round or, equivalently, the chance they will win their first matchup. The probabilities range from 0 to 1 with, for example, .54 indicating a 54 percent chance of the team successfully making it to the second round. The following columns will give the chance that the team appears in each of the subsequent rounds of the tournament, and the final column gives the probability that the team will be named champions. The chance any given team will appear in the second round (Round of 32) is greater than the chance they will appear in the third round (Sweet Sixteen), which is, in turn, greater than the chance they will appear in the fourth round (Elite Eight) and so on. According to this table, Virginia has the highest chance (99.2 percent) of winning their first game and making it to the second round and a 28.66 percent chance of winning the whole tournament.
What exactly determined these probabilities?
I pulled data on kenpom.com and masseyratings.com and used JMP statistical software to look for correlations between over 50 team and player stats and game outcomes. Sometimes there is a clear correlation that can easily be modeled by a linear regression: for example, points per possession is strongly correlated to winning games. Other statistics are more complicated: for example, player experience doesn’t always strongly correlate to success. The best teams are often either heavy with “one-and-done” freshmen or loaded with experienced upperclassmen. JMP tools showed that the relationship between player experience and success was best modeled by a quadratic, not linear, equation. It was also important to be careful of team statistics that were highly correlated with each other. For example, my team’s turnovers and my opponents’ steals essentially measure the same component of the game—including both statistics would run the risk of overweighting the importance that component.
I used a Python program to implement the logistic regression I designed to predict every possible tournament matchup. In later rounds of the tournament it is important to note that we are dealing with compounding probabilities. There are multiple possible opponents a team could face in a later round so the probability they will win is the summation of the probability they will beat each potential opponent multiplied by the chance they will make it to the game, multiplied by the chance that that opponent will appear in the game. The final results were formatted in Tableau to create the above table.
How is this model different than other prediction methods?
There have been many, many previous efforts to correlate team and player statistics with winning games and use to regressions to predict future games. For the most part the quality of the two teams (dictated by their season stats) does a good job of indicating who is likely to win, but sometimes teams with worse stats beat teams with better stats, and sometimes those results are predictable. Most sports analysts would call those games “bad matchups.” My go-to example is Villanova and Butler. Over the past four years, Villanova has maintained a stronger statistical profile and consistently placed well above Butler in rankings and polls, but dropped three games in a row to Butler in 2017. That type of result inspired me to look for correlations between two teams’ stat differentials and result. Instead of a regression that predicts “how likely is a team this good to beat a team that good?” I wanted a regression that looked at “how likely is this team to win against a team that’s this much better than them at shooting free throws and this much worse at causing turnovers?” If another team popped up in the tournament that was clearly statistically inferior to Villanova but was strong in the same categories as Butler, my algorithm would have a better chance of picking up that potential upset.
Why publish probabilities and not just predict winners?
College basketball is inherently unpredictable, but analysts have shown both success and improvement. There certainly are methods that provide vast advantages over a 50-50 coin toss and some prediction algorithms have demonstrated upwards of 70 percent accuracy over tens of thousands of games. With better data and methods, accuracy has and likely will continue to improve, but the consensus is that the cap is well below perfection. There will never be a way to fully account for the freak accidents, the emotions, the technical failures, and other “uncountables” that can affect the outcome of a game. I’m personally inclined to believe that college basketball is no more than 80 percent predictable. A list of only predicted winners undoubtedly contains incorrect results and there would be no way to help you identify which those might be. Publishing a list of probabilities gives you an idea of which games are more competitive and likely to go either way.
How do I turn this information into a bracket?
The simplest way to translate this information into picks for your bracket would be to advance all the teams on your bracket with probability greater than .50 (fifty percent) of appearing in the second round, then advance the all the teams with greater than .50 probability of making the third round and so on. Will this deliver a perfect bracket? Almost certainly not. Even if every probability was spot on (i.e., every team the algorithm gives a .25 probability of advancing actually has an exactly 25 percent chance) the chance that the more likely team would win in every matchup would still be 1 in a couple million. This table of probabilities will probably favor more than a couple losing teams and you are smart enough to pick some of those games. Perhaps a team is favored but their best player has a nagging injury and has under-performed the last few games, or perhaps a team isn’t favored but has just been gifted with a tournament location 20 miles from campus giving them pseudo-home court advantage. Another thing to think about is the value of predicting upsets, which in many bracket contests are rewarded with bonus points. It could be a smart idea to bet on a 12 seed that is given .4 probability because the expected return is higher than the safer five seed (compute .4 x reward for picking upset versus .6 x reward for picking winning high seed). There’s a lot to think about and the optimal way to think of this table is as a tool, not an authority.
What about the play-in games?
The March Madness Tournament actually begins with 60 teams set and four spots to be filled by the winners of four play-in games. This aspect was very difficult to build into my prediction table because the four play-in winners are not slotted into the same places in the bracket every year (sometimes more than one are put into the same region and none into another region). Thus I wrote my program to handle a 64-team single elimination tournament and predicted the play in games separately, using the same logistic regression based algorithm. The predicted winners of the play in games are among the teams included in table.
Photo: (cc) Phil Roeder/Flickr